Athena
This page will walkthrough the setup of Athena in K using the direct connect method
Integration details
Scope | Included | Comments |
|---|---|---|
Metadata | YES | |
Lineage | YES | |
Usage | YES | |
Sensitive Data Scanner | N/A |
Step 1: Establish Athena Access
It is advised you create a new Role and a separate s3 bucket for the service user provided to KADA and have a policy that allows the below, see Identity and access management in Athena - Amazon Athena
The service user/account/role will require permissions to the following
Execute queries against Athena with access to the INFORMATION_SCHEMA in particular the following tables:
information_schema.views
information_schema.tables
information_schema.columns
Executing queries in Athena requires an s3 bucket to temporarily store results. We will also require the policy to allow Read Write Listing access to objects within that bucket, conversely, the bucket must also have policy to allow to do the same.
Call the following Athena APIs (Note that access to Athena metadata through the below APIs will also require access to the Glue catalog).
The service user/account/role will need permissions to access all workgroups to be able to extract all data, if you omit workgroups, that information will not be extracted and you may not see the complete picture in K.
See IAM policies for accessing workgroups - Amazon Athena on how to add policy entries to have fine grain control at the workgroup level. Note that the extractor runs queries on Athena, If you do choose to restrict workgroup access, ensure that Query based actions (e.g. StartQueryExecution) are allowed for the workgroup the service user/account/role is associated to.
Note that user usage will be associated to the workgroup level rather than individual users, these workgroups are published as users in K in the form “athena_workgroup_<name>”
Example Role Policy to allow Athena Access with least privileges for actions, this example allows the ACCOUNT ARN to assume the role. Note the variables ATHENA RESULTS BUCKET NAME. You may also choose to just assign the policy directly to a new user and use that user without assuming roles. In the scenario you do wish to assume a role, please note down the role ARN to be used when onboarding/extracting
AWSTemplateFormatVersion: "2010-09-09"
Description: 'AWS IAM Role - Athena Access to KADA'
Resources:
KadaAthenaRole:
Type: "AWS::IAM::Role"
Properties:
RoleName: "KadaAthenaRole"
MaxSessionDuration: 43200
Path: "/"
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: "Allow"
Principal:
AWS: "[ACCOUNT ARN]"
Action: "sts:AssumeRole"
KadaAthenaPolicy:
Type: 'AWS::IAM::Policy'
Properties:
PolicyName: root
PolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action:
- athena:BatchGetQueryExecution
- athena:GetQueryExecution
- athena:GetQueryResults
- athena:GetQueryResultsStream
- athena:ListQueryExecutions
- athena:StartQueryExecution
- athena:ListWorkGroups
- athena:ListDataCatalogs
- athena:ListDatabases
- athena:ListTableMetadata
Resource: '*'
- Effect: Allow
Action:
- glue:GetDatabase
- glue:GetDatabases
- glue:GetTable
- glue:GetTables
- glue:GetPartition
- glue:GetPartitions
Resource: '*'
- Effect: Allow
Action:
- s3:GetBucketLocation
- s3:GetObject
- s3:ListBucket
- s3:ListBucketMultipartUploads
- s3:ListMultipartUploadParts
- s3:AbortMultipartUpload
- s3:PutObject
- s3:PutBucketPublicAccessBlock
- s3:DeleteObject
Resource:
- arn:aws:s3:::[ATHENA RESULTS BUCKET NAME]
Roles:
- !Ref KadaAthenaRoleAlternatively, the following managed policy will also provide the necessary permissions for the collector - https://docs.aws.amazon.com/aws-managed-policy/latest/reference/AmazonAthenaFullAccess.html
aws iam attach-role-policy \
--role-name YOUR_ROLE_NAME \
--policy-arn arn:aws:iam::aws:policy/AmazonAthenaFullAccessAfter this step you should have the following information
Athena User
Role
Key
Secret
Athena S3 bucket location
Step 2: Create the Source in K
Create an Athena source in K
Select Platform Settings in the side bar
In the pop-out side panel, under Integrations click on Sources
Click Add Source and select Athena
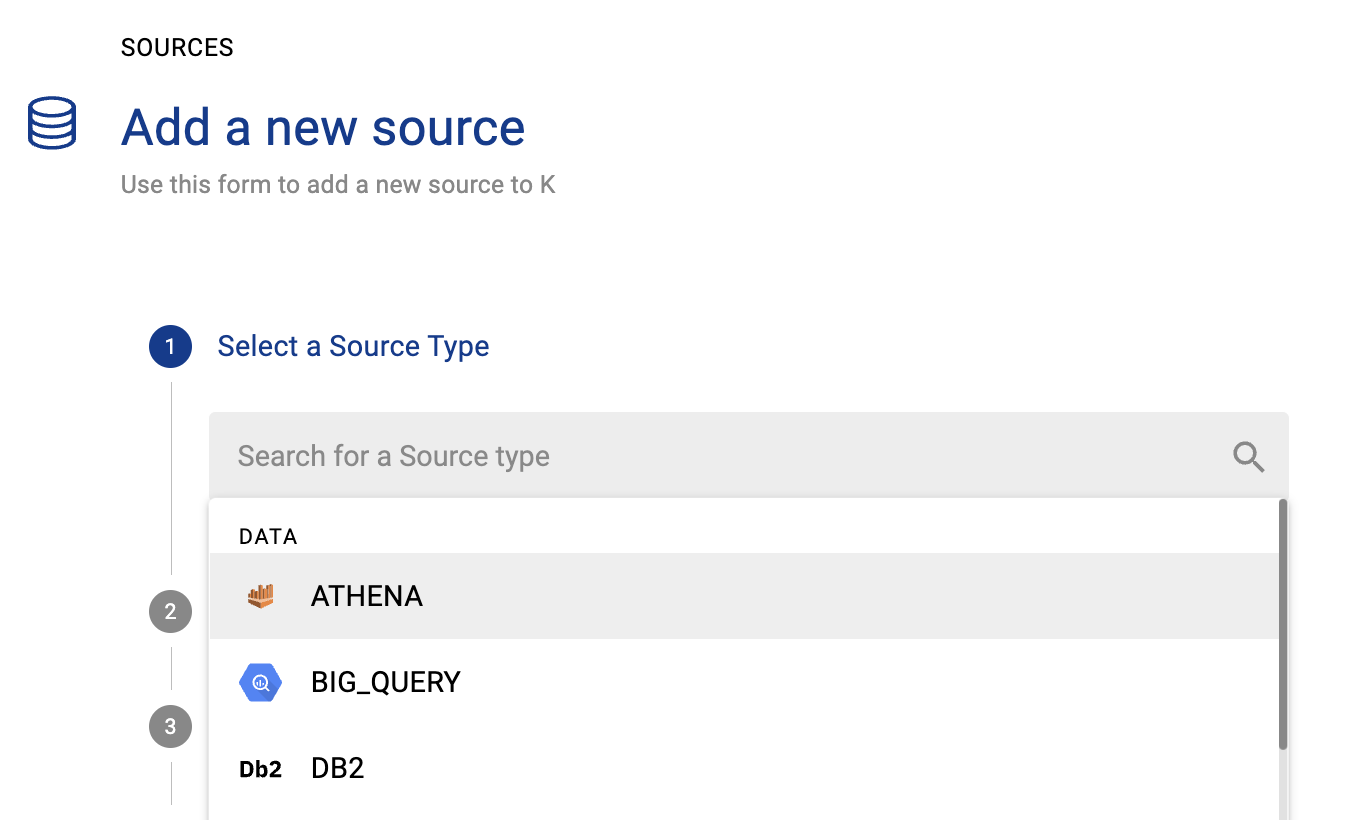
Select Direct Connect and add your Athena details
Name: Give the Athena source a name in K.
Host: Enter a hostname for your Athena instance
Region: Set the region for AWS for where Athena exists e.g. ap-southeast-2
Athena Results bucket: Bucket location used to temporarily store Athena query results. Use the full path starting with s3://
Add Connection Details and click Save & Next
Assume Role: Add the Role from Step 1
Key: Add the Key from Step 1
Secret: Add the Secret from Step 1
Test your connection and click Next.
Click Finish Setup
Step 3: Schedule Athena source load
Select Platform Settings in the side bar
In the pop-out side panel, under Integrations click on Sources
Locate your new Athena Source and click on the Schedule Settings (clock) icon to set the schedule
Step 4: Manually run an ad hoc load to test Athena
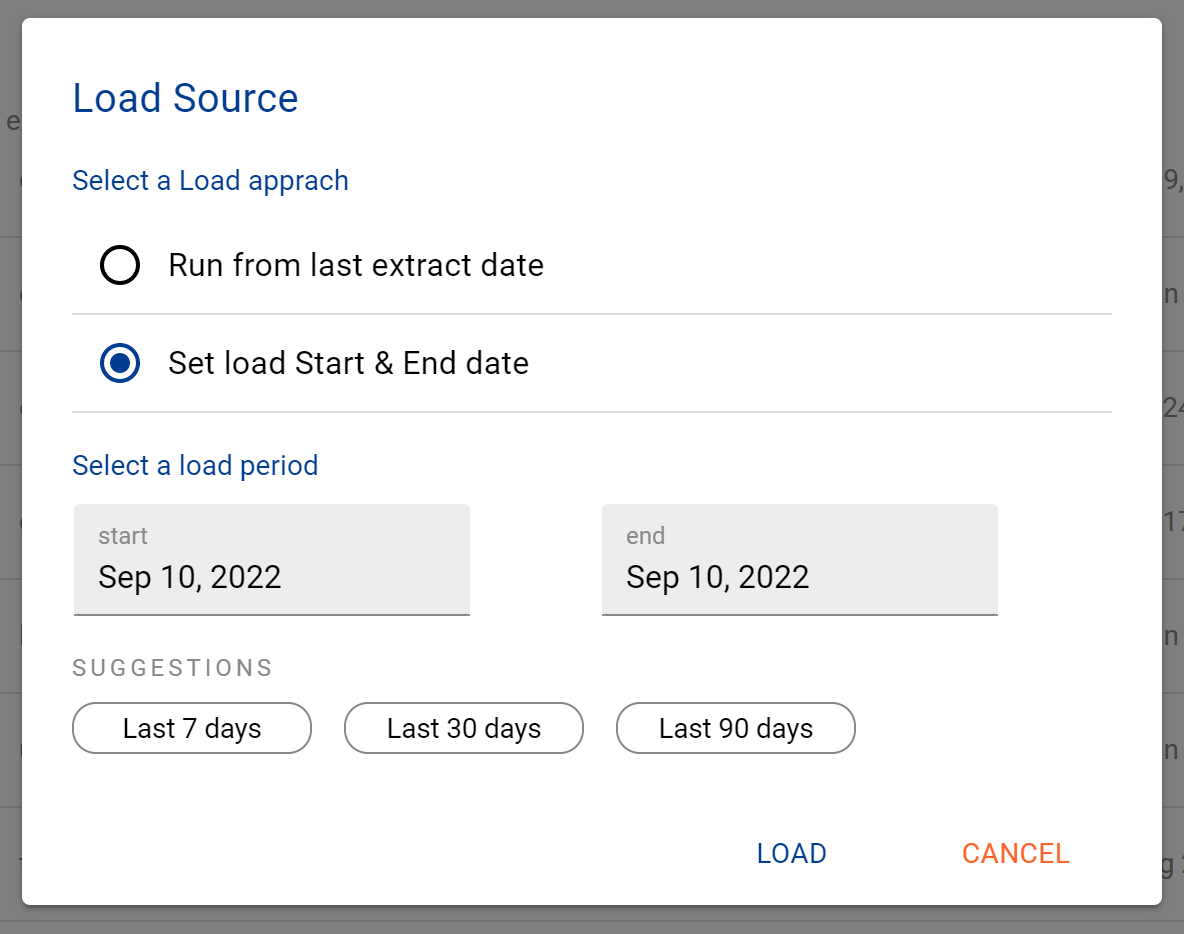
Next to your new Source, click on the Run manual load icon
Confirm how your want the manual run to be completed
After the source load is triggered, a pop up bar will appear taking you to the Monitor tab in the Batch Manager page. This is the usual page you visit to view the progress of source loads
A manual source load will also require a manual run of
DAILY
GATHER_METRICS_AND_STATS
To load all metrics and indexes with the manually loaded metadata. These can be found in the Batch Manager page
Troubleshooting failed loads
If the job failed at the extraction step
Check the error. Contact KADA Support if required.
Rerun the source job
If the job failed at the load step, the landing folder failed directory will contain the file with issues.
Find the bad record and fix the file
Rerun the source job