Hevo
This page will walkthrough the setup of Hevo in K using the direct connect method.
Integration details
Scope | Included | Comments |
|---|---|---|
Metadata | YES |
|
Lineage | YES |
|
Usage | NO | Usage currently not captured for pipeline runs |
Sensitive Data Scanner | N/A |
|
Known limitations
Not all sources and destinations are currently covered. A future improvement is planned to cover sources & destinations generically.
Current sources implemented
AZURE_SQL
BIGQUERY
FTP
JIRA_CLOUD
MS_SQL
RESTAPI
Current destinations supported
SNOWFLAKE
Step 1) Create an API Key
The Hevo documentation for creating an API Key is here https://api-docs.hevodata.com/reference/building-your-first-api
Log into your Hevo account and go to Account. Go to the API Keys to generate a New API Key.
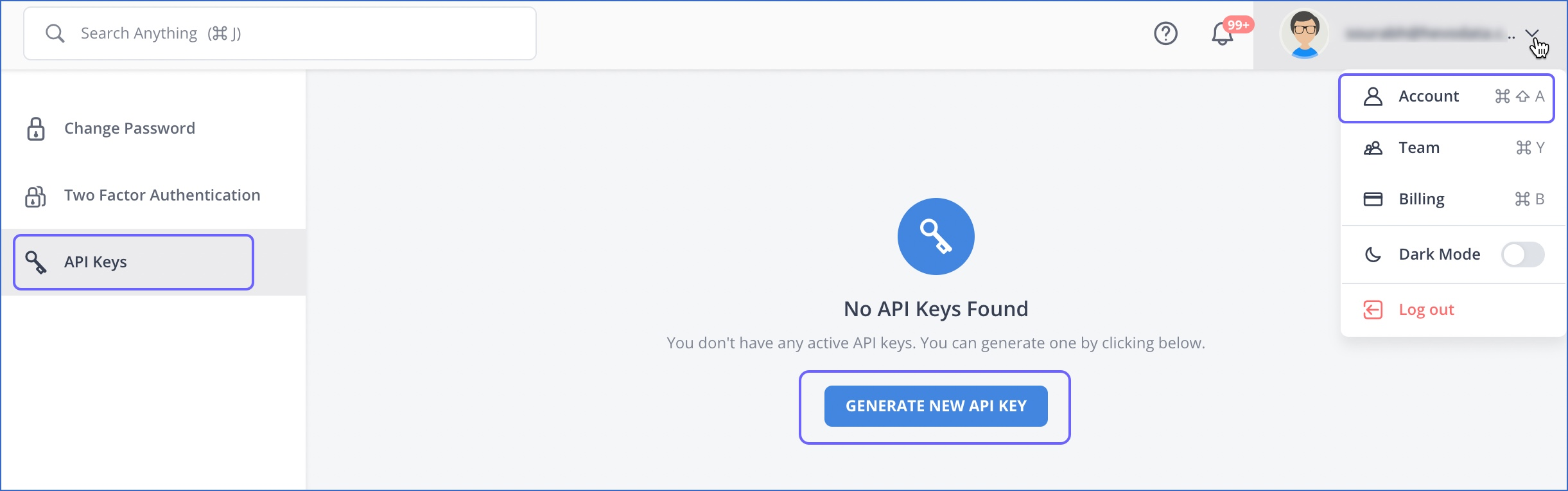
Copy the Access Key and Secret Key.
Step 2) Add Hevo as a New Source
Select Platform Settings in the side bar
In the pop-out side panel, under Integrations click on Sources
Click Add Source and select Hevo
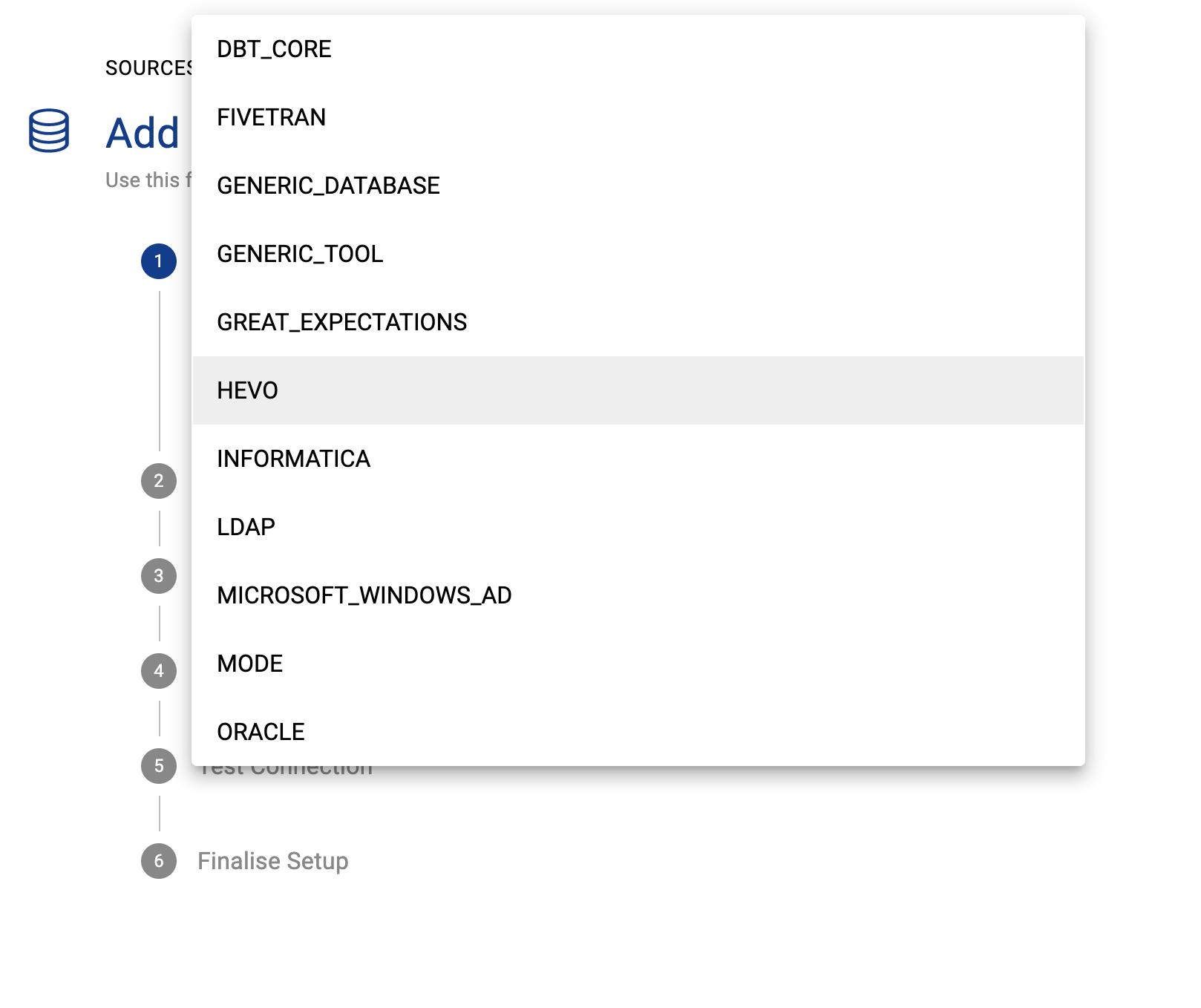
Select Direct Connect and add your Hevo details and click Next
Fill in the Source Settings and click Save & Next
Name: Give the Hevo source a name in K
Host: Can be any unique value. For example add
asia.hevodata.comUpdate the Host / Database mapping - see Host / Database Mapping. This step can be completed after the initial load via the guided workflow.
Add your Access Key (Client ID) and Secret Key (Client Secret) copied from Step 1 and click Save
Test your connection and click Save
Click Finish Setup
Step 3) Schedule Hevo source load
Select Platform Settings in the side bar
In the pop-out side panel, under Integrations click on Sources
Locate your new Hevo source and click on the Schedule Settings (clock) icon to set the schedule
Note that scheduling a source can take up to 15 minutes to propagate the change.
Step 4) Manually run an ad hoc load to test Hevo setup
Next to your new Source, click on the Run manual load icon

Confirm how your want the source to be loaded
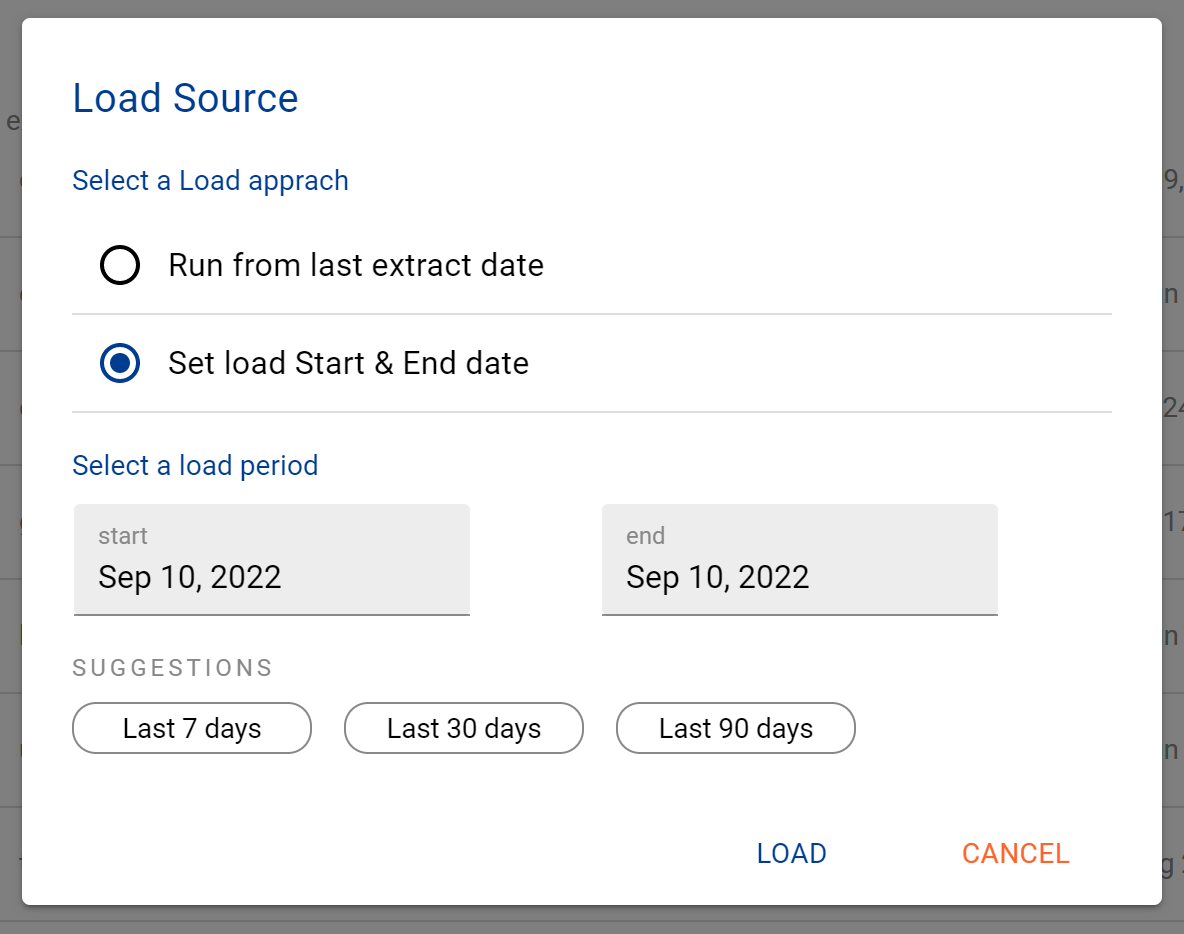
After the source load is triggered, a pop up bar will appear taking you to the Monitor tab in the Batch Manager page. This is the usual page you visit to view the progress of source loads

A manual source load will also require a manual run of
DAILY
GATHER_METRICS_AND_STATS
To load all metrics and indexes with the manually loaded metadata. These can be found in the Batch Manager page
Troubleshooting failed loads
If the job failed at the extraction step
Check the error. Contact KADA Support if required.
Rerun the source job
If the job failed at the load step, the landing folder failed directory will contain the file with issues.
Find the bad record and fix the file
Rerun the source job