Redshift
This page will guide you through the setup of Redshift in K using the direct connect method.
Integration details
Scope | Included | Comments |
|---|---|---|
Metadata | YES |
|
Lineage | YES |
|
Usage | YES | |
Sensitive Data Scanner | YES |
|
Step 1) Establish Redshift Access
There are 2 methods for providing K access to Redshift: Super user or Custom user.
Super user method: Create a new Superuser - refer to https://docs.aws.amazon.com/redshift/latest/dg/r_superusers.html to view all required data.
ALTER USER <kada user> CREATEUSER; -- GRANTS SUPERUSERCustom user methods: Create a user with
Unrestricted SYSLOG ACCESS - refer to https://docs.aws.amazon.com/redshift/latest/dg/c_visibility-of-data.html. This will allow full access to the STL tables for the user.
SQLALTER USER <kada user> SYSLOG ACCESS UNRESTRICTED; -- GRANTS READ ACCESSSelect Access to existing and future tables in all Schemas for each Database you want K to ingest.
List all existing Schema in the Database by running
SQLSELECT DISTINCT schema_name FROM svv_all_tables; -- LIST ALL SCHEMASFor each schema above do the following to allow the kada user select access to all tables inside the Schema and any new tables created in the schema thereafter.
You also must do this for ANY new schemas created in the Database to ensure K has view of it.
SQLGRANT USAGE ON SCHEMA <schema name> TO <kada user>; GRANT SELECT ON ALL TABLES IN SCHEMA <schema name> TO <kada user>; ALTER DEFAULT PRIVILEGES IN SCHEMA <schema name> GRANT SELECT ON TABLES TO <kada user>;
The PG tables are granted per database but generally all users should have access to them on DB creation. In the event the user doesn’t have access, explicit grants will need to be done per new DB in Redshift.
GRANT USAGE ON SCHEMA pg_catalog TO <kada user>;
GRANT SELECT ON ALL TABLES IN SCHEMA pg_catalog TO <kada user>;The user used for the extraction must also be able to connect to the the databases needed for extraction.
System Tables
svv_all_columns
svv_all_tables
svv_tables
svv_external_tables
svv_external_schemas
stl_query
stl_querytext
stl_ddltext
stl_utilitytext
stl_query_metrics
stl_sessions
stl_connection_log
PG Tables
pg_class
pg_user
pg_group
pg_namespace
pg_proc
Step 2) Connecting K to Redshift
Select Platform Settings in the side bar
In the pop-out side panel, under Integrations click on Sources
Click Add Source and select Redshift
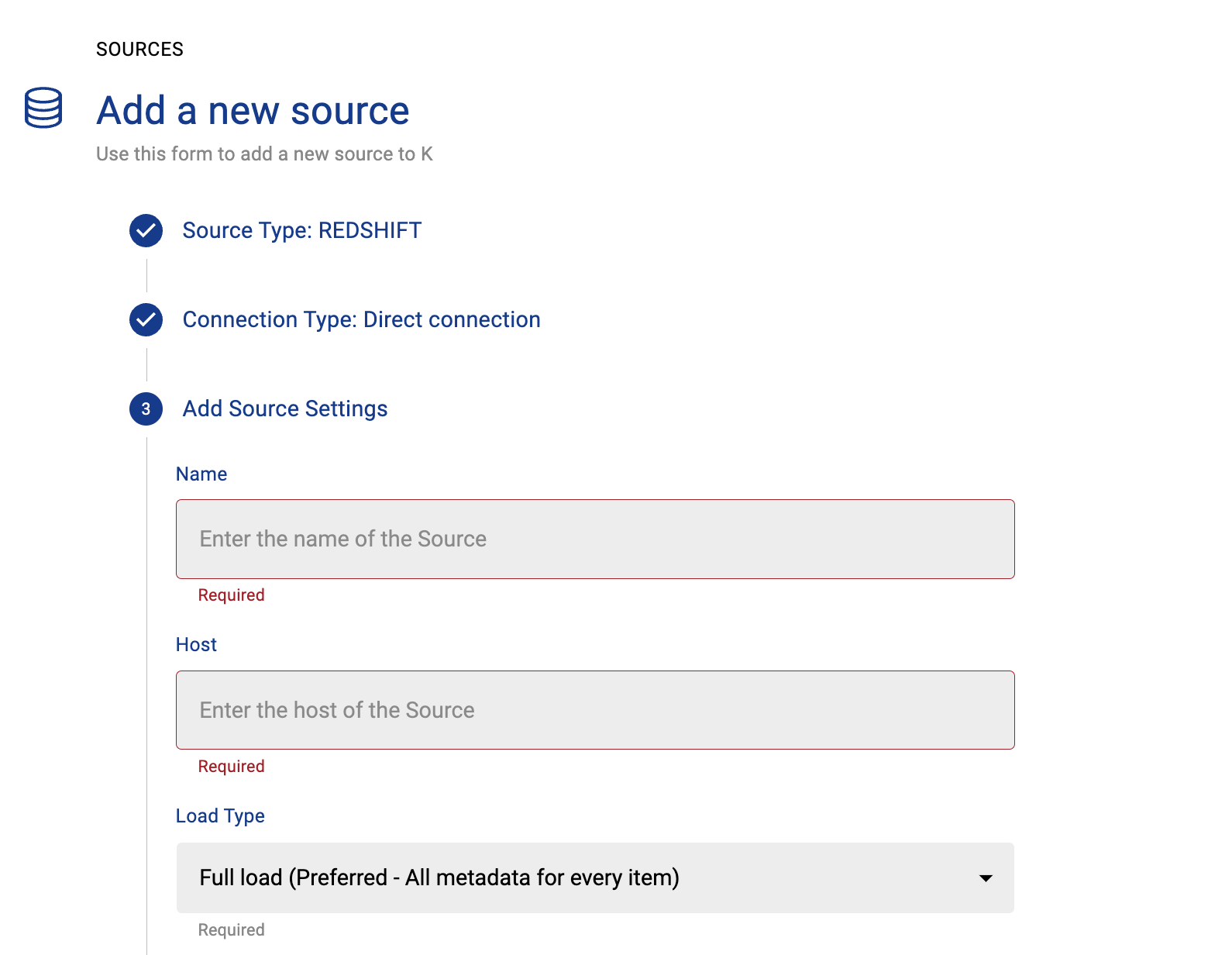
Select Direct Connect and add your Redshift details and click Next
Fill in the Source Settings and click Next
Name: The name you wish to give your Redshift Instance in K
Host: Add your Redshift host (found in your Redshift URL)
Omit the https:// from the URL
Add the Connection details and click Save & Next when connection is successful
Host: Use the same details you previously added in the Host setting
Username: Add the Redshift user name you created in Step 1
Password: Add the Redshift user password you created in Step 1
Test your connection and click Save
Select the Databases you wish to load into K and click Finish Setup
All databases will be listed. If you have a lot of databases this may take a few seconds to load
Return to the Sources page and locate the new Redshift source that you loaded
Click on the clock icon to select Edit Schedule and set your preferred schedule for the Snowflake load
Note that scheduling a source can take up to 15 minutes to propagate the change.
Step 3) Manually run an ad hoc load to test Redshift setup
Next to your new Source, click on the Run manual load icon

Confirm how your want the source to be loaded
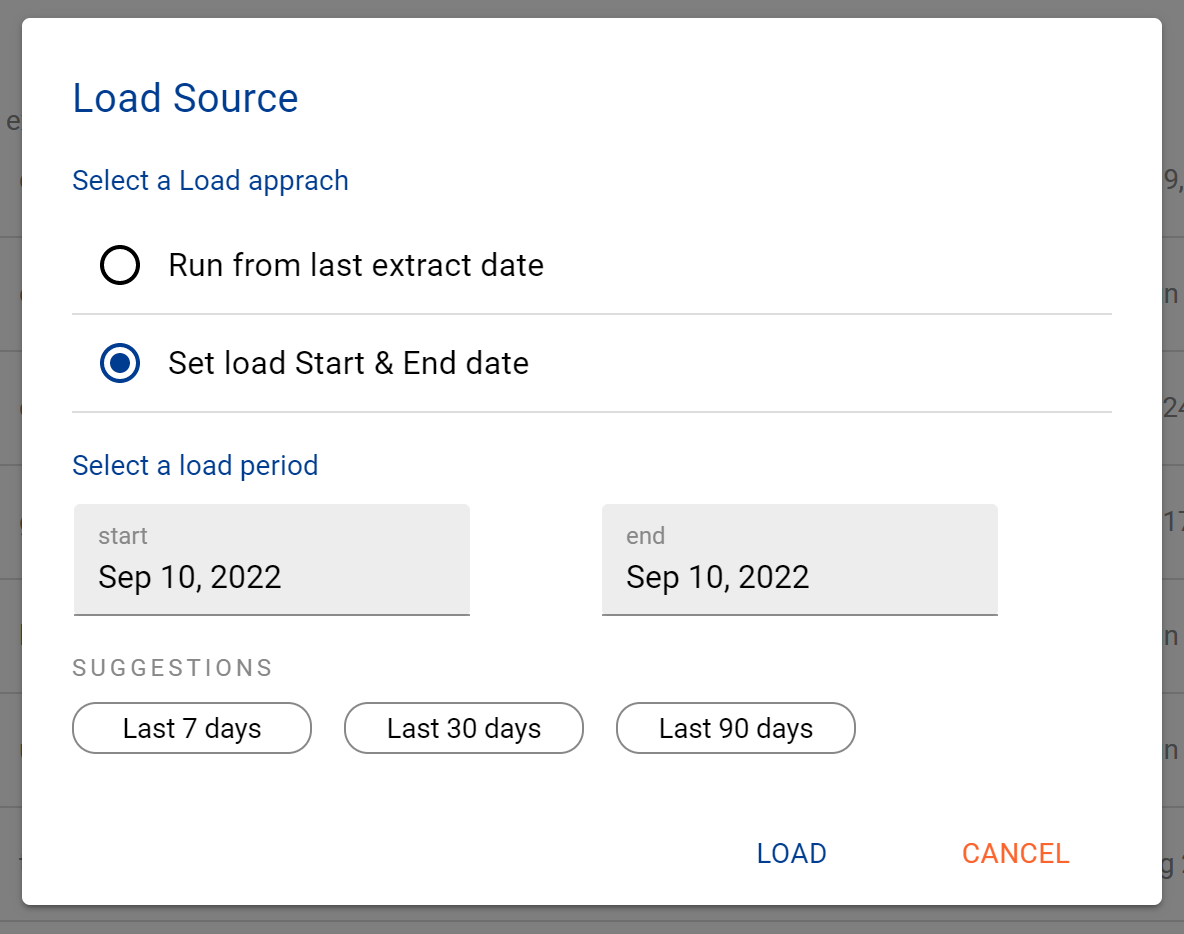
After the source load is triggered, a pop up bar will appear taking you to the Monitor tab in the Batch Manager page. This is the usual page you visit to view the progress of source loads

A manual source load will also require a manual run of
DAILY
GATHER_METRICS_AND_STATS
To load all metrics and indexes with the manually loaded metadata. These can be found in the Batch Manager page
Troubleshooting failed loads
If the job failed at the extraction step
Check the error. Contact KADA Support if required.
Rerun the source job
If the job failed at the load step, the landing folder failed directory will contain the file with issues.
Find the bad record and fix the file
Rerun the source job