Sensitive Data (e.g. PII) Scanner
Pre-requisites
Python 3.6 - 3.10 (excluding 3.9.0)
Note: 3.9.0 is unsupported. 3.9.1 and subsequent versions are supported.
Access to K landing directory
Read access to the source that you are going to run the PII Scanner against.
Install the corresponding collector package for the source you are scanning.
For example if you are scanning snowflake, you need to also install the Snowflake collector package.
If you would like to run the PII scanner on multiple sources, then you will need to install the collector package for all sources
Refer to the Source collector page for instructions on how to install collector packages. e.g. Snowflake (via Collector method) , Redshift (via Collector method) , Oracle Database (via Collector method)
Limitations
The Scanner has a number of known limitations
The following scenarios will result in a FAILED scan status by the scanner.
Unable to scan tables with case sensitive names thats usually controlled by quoting in the SQL
Unable to scan tables with special characters that break SQL format without quoting
Unable to scan tables that are named after keywords which require quoting
Unable to scan tables (inclusive of the schema and database names that the table belongs to) that contain a period (.) in the name.
If the table contains a column that causes a data retrieval error
If the view has issues executing the underlying Stored Proc or SQL
Significant improvements to the scanner is planned for Q4 24 and Q1 25.
Step 1: Generate a scanner configuration
The scanner configuration is generated for all tables in a database or schema within a database source. A future enhancement (Q1 2024) will allow for additional custom table selection.
Log into K and go to Data Applications. Select Ask K
Select the scanner tab. Go to the Scanner config and click on Run
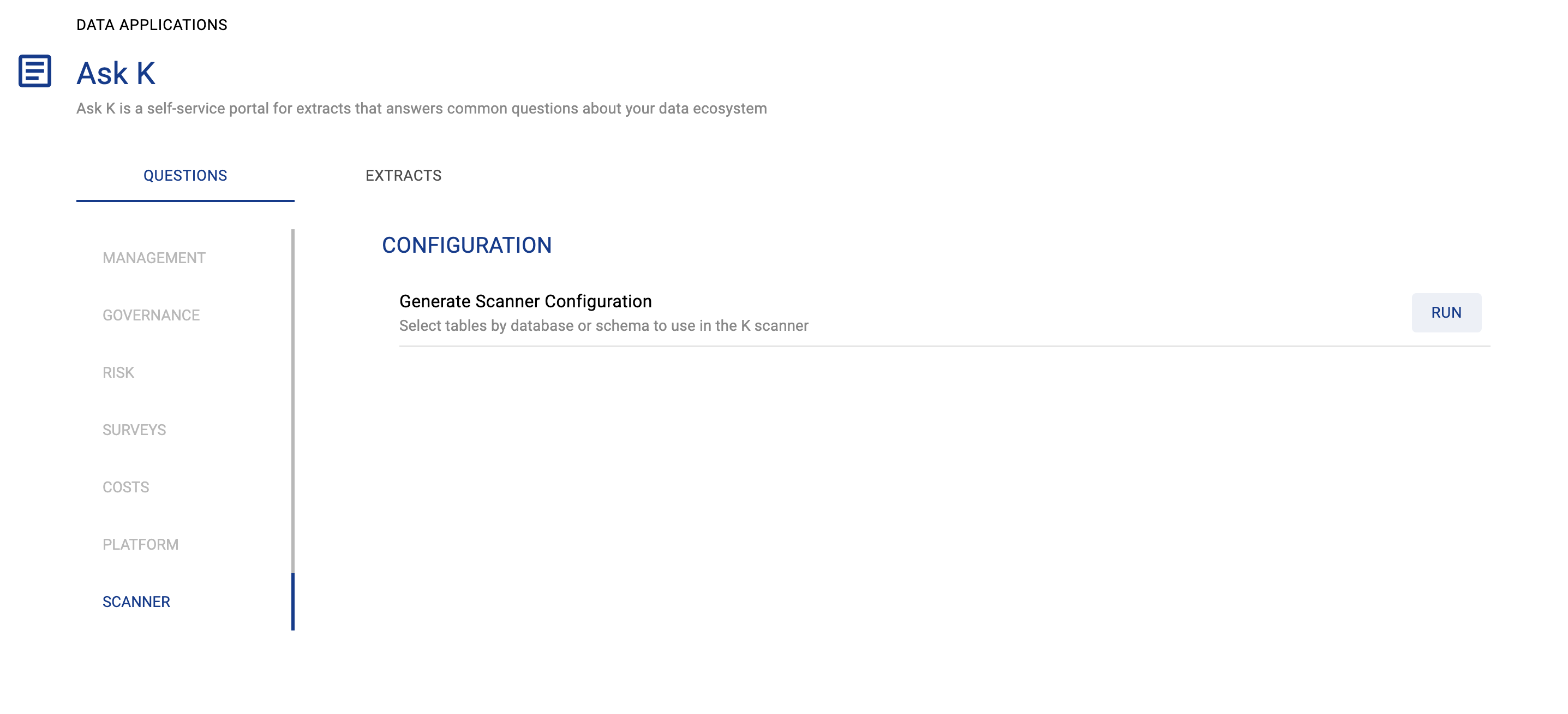
Select the source and tables you want to run the scanner on. You can select all the tables by database or schema.
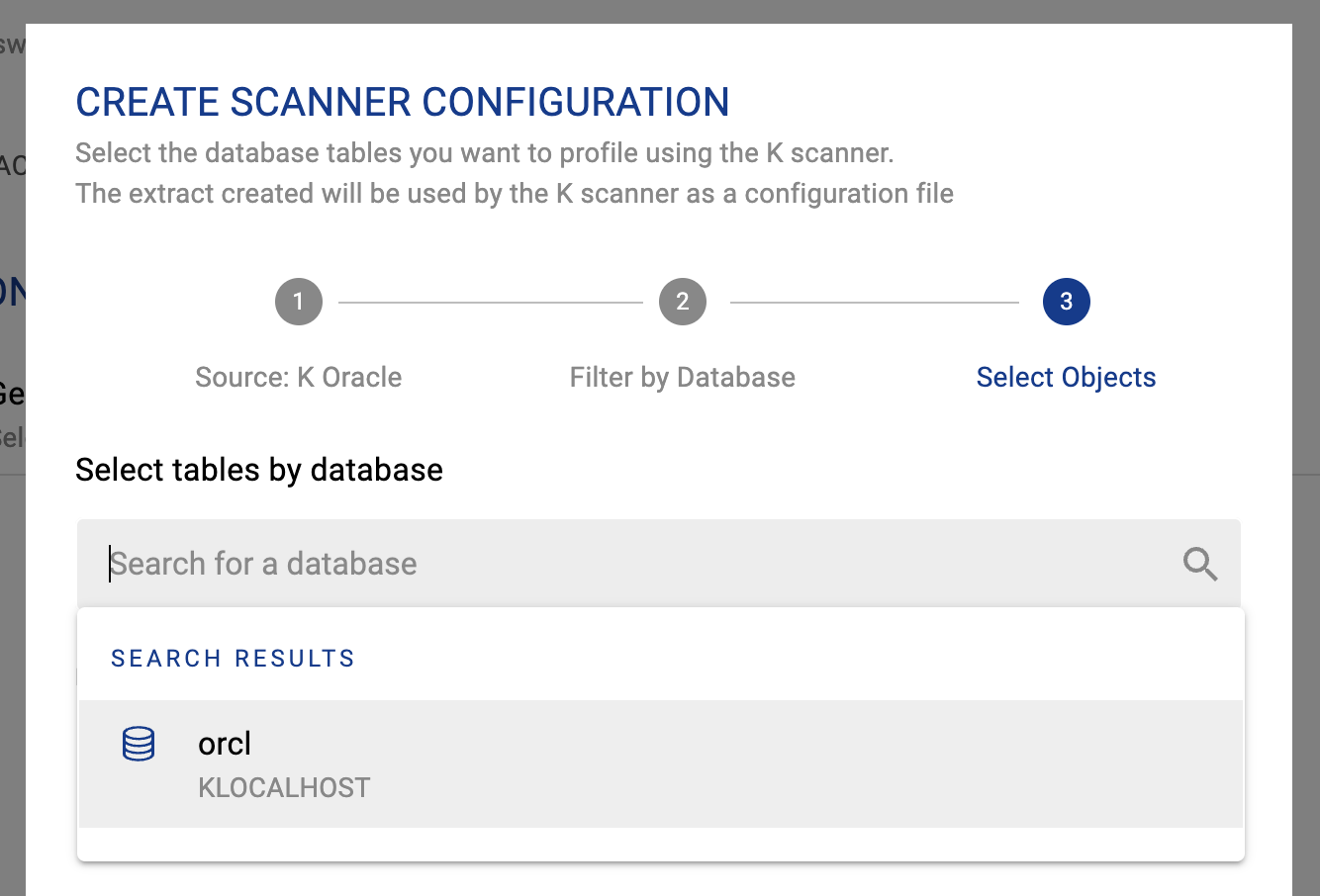
Click Create to generate the scanner config to be used in the scanner.
Step 1: Install the PII Scanner Collector
The PII Scanner Collector is currently hosted in KADA’s Azure Blob Storage. Reach out to KADA Support (support@kada.ai) to obtain the collector package and receive a SAS token to access the repository.
Make sure that you’ve already set up the collector packages for the Sources (e.g. Snowflake) that you’d like to run the PII Scanner Collector on.
Step 2: Configure the Collector
Check to ensure that the following steps have been completed:
Installed the relevant Source Collector .whl
Installed any external dependencies described on the Source Collector page.
Installed the common library package
kada_collectors_lib-<version>-py3-none-any.whlor higherInstalled the PII Scanner .whl (as per Step 1)
Created the Source Collector config json file as described on the Source Collector page
The following code is an example of how to run the extractor targeting Snowflake as the source. You may need to uplift this code to meet any code standards at your organisation.
This is the wrapper script: kada_pii_scanner.py
import csv
import argparse
from kada_collectors.extractors.utils import load_config, get_generic_logger
from kada_collectors.extractors.pii_scanner import PIIScanner, VALID_DEFAULT_DETECTORS
get_generic_logger('root') # Set to use the root logger, you can change the context accordingly or define your own logger
parser = argparse.ArgumentParser(description='KADA PII Scanner.')
parser.add_argument('--extractor-config', '-e', dest='extractor_config', type=str, required=True, help='Location of the extarctor configuration json.')
parser.add_argument('--objects-file-path', '-f', dest='objects_file_path', type=str, required=True, help='Location of the .txt file that contains the list of objects to scan for the source.')
parser.add_argument('--source-type', '-t', dest='source_type', type=str, required=True, help='What kind of source are we scanning? E.g. snowflake, oracle etc. See documentation for full list of supported source types.')
parser.add_argument('--sample-size', '-s', dest='sample_size', type=int, required=True, help='How many rows are we sampling for each object, note that 0 means all rows will be sampled, number should be greater or equal to 0.')
parser.add_argument('--parrallel', '-p', dest='concurrency', type=int, default=1, help='Should it be running in parallel, default is 1 meaning no parallelism, consider your CPU resources when settings this value.')
parser.add_argument('--default-detectors', '-d', dest='default_detectors', type=str, help='Comma seperated list of default detectors the scanner should use {}'.format(','.join(VALID_DEFAULT_DETECTORS)))
parser.add_argument('--delta', '-a', dest='delta', action='store_true', help='Produces a DELTA extract file if you are doing a partial scan.')
parser.add_argument('--pii-output-path', '-o', dest='pii_output_path', type=str, required=True, help='The output path to the folder where the extract should appear.')
args = parser.parse_args()
# ######
# Impliment additional logic for checking existence if you wish
# You may also choose to call the PIIScanner differently and not use an input file this is completely up to you
# You can also feed in from your own custom producer for the list of objects
# This is simply the default out of the box implimentation to call the PIIScanner and produce the required Extract File for K
# ######
def read_validate_object_file(file_path):
"""
Reads the flat file and validates the header and returns an iterator
This is simply the out of the box way to feed the scanner, you may choose a different
way to feed the scanner
"""
with open (file_path, 'r', encoding='utf-8') as csv_file:
reader = csv.reader(csv_file, delimiter=',')
header = next(reader) # Skip the header
if [x.upper() for x in header] != ['OBJECT_TYPE','OBJECT_ID']: # Should be a flat file thats comma delimited with the headers OBJECT_TYPE and OBJECT_ID
raise Exception('Invalid object file')
return [x for x in reader] # Return a list not an iterator as we will close the file
if __name__ == '__main__': # Do not omit this syntax as the Class impliments multiprocessing
extractor_config = load_config(args.extractor_config) # Load the corresponding collector config file
object_list = read_validate_object_file(args.objects_file_path) # 2D Array of objects
# You can define your own Detector classes and register them before calling .scan() method to ensure the scanner picks up the new Detector Class, read the documentation on how to impliment new classes
# You'll need to decorate the class with kada_collectors.extractors.pii_scanner.register_detector
default_detectors = [x.strip() for x in args.default_detectors.split(',')] if args.default_detectors else []
pii_scanner = PIIScanner(args.source_type, args.sample_size, args.concurrency, object_list, args.pii_output_path, default_detectors=default_detectors, delta=args.delta, **extractor_config)
pii_scanner.scan()This can be executed anywhere provided it has the wheels installed. And can be called by running.
python kada_pii_scanner.py -e ./kada_snowflake_extractor_config.json -f ./pii_test_scan.csv -t snowflake -s 10 -p 8 -o /tmp/output -d Email,AUPhoneNumber,CreditCard,AUTaxFileNumber,AUZipCode,AUDriversLicense,AUMedicare,AUPassport,AUABN,IPAddressArguments are as follows, you can view these by calling help in the default wrapper script
python kada_pii_scanner.py --helpARGUMENT | SHORT ARGUMENT | TYPE | OPTIONAL | DESCRIPTION | EXAMPLE |
|---|---|---|---|---|---|
--extractor-config | -e | STRING | N | Location of the extractor configuration json. | /tmp/kada_snowflake_collector_config.json |
--objects-file-path | -f | STRING | N | Location of the .txt file that contains the list of objects to scan for the source. See reference section below for a sample file. This is applicable when using the default wrapper script. | /tmp/object_list.csv |
--source-type | -t | STRING | N | What kind of source are we scanning? E.g. snowflake, oracle etc. See documentation for full list of supported source types. See reference section below. | snowflake |
--sample-size | -s | INTEGER | N | How many rows are we sampling for each object, note that 0 means all rows will be sampled, number should be greater or equal to 0. | 10 |
--parallel | -p | INTEGER | Y | Should it be running in parallel, default is 0 meaning no parallelism, consider your CPU resources when settings this value. Also see the warning below. | 4 |
--default-detectors | -d | LIST<STRING> comma seperated | This is mandatory unless custom detectors are defined. | This lists all the out of the box default detectors that should be run, should be a comma separated list of the following values
CODE
see Advanced Usage for how to define your own Detectors and not just use out of the box ones. | Email,AUPhoneNumber,CreditCard,AUTaxFileNumber,AUDriversLicense,AUMedicare,AUPassport,AUAddress,AUABN,IPAddress |
--delta | -a | FLAG | Y | If this flag is specified the collector will produce a DELTA file, use this flag if you are not intending to scan everything that’s loaded in K, note that producing DELTAs means K won’t know what has changed and it will only upsert your extract. | N/A |
--pii-output-path | -o | STRING | N | The path to the output folder for the PII extract, note this folder will be cleared during the extraction process so choose carefully. | /tmp/output |
When setting the parallel argument don’t just consider your own CPU but also the resources available on the Database. E.g. if you have enough CPU to do 16 threads and the Database can only service 2 simultaneous queries, the 16 threads is useless and bottlenecked on the Database side as the queries will queue, so keep this in mind when considering performance.
Step 3 (Optional): Defining your own Detectors
The out of the box detectors include the following:
AUAddress - Australian Addresses
Email - General Emails
CreditCard - General Credit Cards
AUTaxFileNumber - Australian Tax File Numbers
AUPhoneNumber - Australian Phone Numbers
AUMedicare - Australian Medicare Numbers
AUPassport - Australian Passport Numbers
AUABN - Australian Business Numbers
IPAddress - IPv4 and IPv6 patterns for IP addresses
AUDriversLicense - Australian Drivers License Numbers
AUNSWDriversLicense (NSW)
AUVICDriversLicense (VIC)
AUQLDDriversLicense (QLD)
AUWADriversLicense (WA)
AUACTDriversLicense (ACT)
Note: Out of the box detectors do not consider the column name in the detection process.
You may choose which default ones you wish to use by passing in a list to the default_detectors value (see Controlling Scanner Inputs in the Advanced Usage Section for the PIIScanner class definition)
Alternatively you may choose to overwrite one of the out of the box detectors, in this case make sure the class name for the detector is the same as the class name of the out of the box detector. To list the names of the out of the box detectors, you can inspect the registry
from kada_collectors.extractors.pii_scanner import PIIScanner
if __name__ == '__main__': # Ensure you have the main syntax or the caller has the main syntax
pii_scanner = PIIScanner(source_type, sample_size, concurrency, object_list, output_path, disable_defaults=False, **extractor_config)
for dets in pii_scanner.registered_detectors.values():
print(dets.keys())You can request a sample custom script from KADA which contains a working copy of different ways to inherit/define your own collectors.
To define your own detector you’ll need to do the following before you instantiate the Scanner class
from kada_collectors.extractors.pii_scanner import PIIScanner, register_detector, DatabaseDatumDetectors, Email
@register_detector
class MyEmailDetector(DatabaseDatumDetectors):
"""
Example implimentation of your own Detector
"""
def detect(self, datum, column_name):
"""
datum: is the data that needs to checked, its up to the detector implimentation to transform the incoming dbapi value type and skip if required
column_name: is the name of the column of which the data belongs to
returns: A list of PIIType Instances that are matched
"""
matches = []
if not isinstance(datum, bool): # We only don't apply to boolean
if '@' in str(datum):
matches.append(pii_cls())
return matches
# Call Scanner class as normal
if __name__ == '__main__': # Ensure you have the main syntax or the caller has the main syntax
pii_scanner = PIIScanner(source_type, sample_size, concurrency, object_list, output_path, disable_defaults=False, **extractor_config)
pii_scanner.scan()Your class must
inherit the DatabaseDatumDetector class
be decorated with the register_detector so the Scanner class knows it exists. If you don’t do this, the scanner will not pick it up. If you don’t inherit the right class it will also fail the registration and cause the following exception
CODEraise ValueError("Detector should be an inherited class of DatabaseDatumDetectors") ValueError: Detector should be an inherited class of DatabaseDatumDetectorsContain the detect method that takes a datum value (it will be up to you to transform this datum value as it can be any type) and the column_name and returns a list of matching PIIType instances, so your Detector can return multiple PIIType matches if needed.
In some cases you may wish to package your detectors, in such scenarios you can continue to use the decorator method via a director call like below
from mypackageofdetectors import MyDetector
from kada_collectors.extractors.pii_scanner register_detector
register_detector(MyDetector)Example: Wrapper with defined Detector and PII Type
Below is an example of a wrapper with a defined Detector and PII Type using the register_detector decorator.
import csv
import argparse
from kada_collectors.extractors.utils import load_config, get_generic_logger
from kada_collectors.extractors.pii_scanner import PIIScanner, register_detector, DatabaseDatumDetectors, PIIType
get_generic_logger('root') # Set to use the root logger, you can change the context accordingly or define your own logger
parser = argparse.ArgumentParser(description='KADA PII Scanner.')
parser.add_argument('--extractor-config', '-e', dest='extractor_config', type=str, required=True, help='Location of the extarctor configuration json.')
parser.add_argument('--objects-file-path', '-f', dest='objects_file_path', type=str, required=True, help='Location of the .txt file that contains the list of objects to scan for the source.')
parser.add_argument('--source-type', '-t', dest='source_type', type=str, required=True, help='What kind of source are we scanning? E.g. snowflake, oracle etc. See documentation for full list of supported source types.')
parser.add_argument('--sample-size', '-s', dest='sample_size', type=int, required=True, help='How many rows are we sampling for each object, note that 0 means all rows will be sampled, number should be greater or equal to 0.')
parser.add_argument('--parrallel', '-p', dest='concurrency', type=int, default=1, help='Should it be running in parallel, default is 1 meaning no parallelism, consider your CPU resources when settings this value.')
parser.add_argument('--default-detectors', '-d', dest='default_detectors', type=str, help='Comma seperated list of default detectors the scanner should use {}'.format(','.join(VALID_DEFAULT_DETECTORS)))
parser.add_argument('--delta', '-a', dest='delta', action='store_true', help='Produces a DELTA extract file if you are doing a partial scan.')
parser.add_argument('--pii-output-path', '-o', dest='pii_output_path', type=str, required=True, help='The output path to the folder where the extract should appear.')
args = parser.parse_args()
# ######
# Impliment additional logic for checking existence if you wish
# You may also choose to call the PIIScanner differently and not use an input file this is completely up to you
# You can also feed in from your own custom producer for the list of objects
# This is simply the default out of the box implimentation to call the PIIScanner and produce the required Extract File for K
# ######
def read_validate_object_file(file_path):
"""
Reads the flat file and validates the header and returns an iterator
This is simply the out of the box way to feed the scanner, you may choose a different
way to feed the scanner
"""
with open (file_path, 'r', encoding='utf-8') as csv_file:
reader = csv.reader(csv_file, delimiter=',')
header = next(reader) # Skip the header
if [x.upper() for x in header] != ['OBJECT_TYPE','OBJECT_ID']: # Should be a flat file thats comma delimited with the headers OBJECT_TYPE and OBJECT_ID
raise Exception('Invalid object file')
return [x for x in reader] # Return a list not an iterator as we will close the file
class MyType(PIIType):
name = 'Me'
@register_detector
class MyEmailDetector(DatabaseDatumDetectors):
"""
Example implimentation of your own Detector
"""
def detect(self, datum, column_name):
"""
datum: is the data that needs to checked, its up to the detector implimentation to transform the incoming dbapi value type and skip if required
returns: A list of PIIType Instances that are matched
"""
matches = []
if not isinstance(datum, bool): # We only don't apply to boolean
if '@' in str(datum):
matches.append(MyType())
return matches
if __name__ == '__main__': # Do not omit this syntax as the Class impliments multiprocessing
extractor_config = load_config(args.extractor_config) # Load the corresponding collector config file
object_list = read_validate_object_file(args.objects_file_path) # 2D Array of objects
# You can define your own Detector classes and register them before calling .scan() method to ensure the scanner picks up the new Detector Class, read the documentation on how to impliment new classes
# You'll need to decorate the class with kada_collectors.extractors.pii_scanner.register_detector
pii_scanner = PIIScanner(args.source_type, args.sample_size, args.concurrency, object_list, args.pii_output_path, disable_defaults=args.disable_defaults, **extractor_config)
pii_scanner.scan()Advanced Usage
Controlling Scanner Inputs
You may have other processes that produce the object list and you would like to control your own way of handling the object list. For these scenarios, the scanner can be called as follows.
from kada_collectors.extractors.pii_scanner import PIIScanner
if __name__ == '__main__': # Ensure you have the main syntax or the caller has the main syntax
extractor_config = {# Your own way of handling extractor configs e.g. ENV variables}
source_type = 'snowflake' # Defintion of these fields are as above in the wrapper table, otherwise see the class defintion below
sample_size = 1
concurrency = 1
object_list = [] # This is a 2D array of objects in the form [[<object_type>, <object_id>]]
pii_scanner = PIIScanner(source_type, sample_size, concurrency, object_list, pii_output_path, disable_defaults=False, detal=False, **extractor_config)
pii_scanner.scan()PIIScanner(source_type: str,
rows: int,
concurrency: int,
object_list: list,
pii_output_path: str,
*args: Any,
default_detectors: list = [],
delta: bool = False,
**kwargs: Any) -> NonePII Scanner is designed to instantiate a scanner per target object
source_type: What kind of source will the scanner be pointing to
rows: How many rows are we sampling? 0 means all rows will be sampled
concurrency: Should the Scanner be running in parallel, 0 means single thread
object_list: 2D array in the form of a list of OBJECT_TYPE and OBJECT_ID,
default_detectors: list of default detectors to run, If this is empty no defaults will run
args and kwargs are passed to the Extractor class, more information can be found on the relevant Collector page for that particular source Extractor.
Controlling the Scan and Extract Process
In some situations you may wish to scan individual sets of objects but not necessarily produce an extract till the end of an orchestration. You can do so by passing in a blank object list to instantiate the class and explicitly call scan_data yourself.
By choosing to use this method, it will bypass input validation and it will be up to you to handle the errors, so be familiar with the inputs to ensure you passing in the right thing.
pii_scanner = PIIScanner('snowflake', 10, 1, [], **extractor_config)
payloads = pii_scanner.scan_data(object_list)Where object list is still the same 2D array, if you want to specify just one object, just place 1 element into the 2D array like so
object_list = [['TABLE','kada_snowflakecomputing_com.dwh.extract.tableA']]The method will return another 2D array which will tell you the object picked up from the scan and any PIITypes associated that was detected. If nothing is detected it will return an empty array. So payloads will look like this if it wasn’t empty.
3dbf7c4f-1d05-3b75-9920-9122e6eaed56 is simply the UUID for K’s internal purposes
[['COLUMN','kada_snowflakecomputing_com.dwh.extract.tableA.col1','3dbf7c4f-1d05-3b75-9920-9122e6eaed56','my detected pii']]Once you have multiple payloads from multiple individual calls, you can combine all the payloads together into a single payload by concatenating the lists together.
final_payloads = payloads1 + payloads2You can then process the final payloads using scan_call_back and produce the extract by calling produce_extract
pii_scanner = PIIScanner('snowflake', 10, 1, [], **extractor_config)
pii_scanner.scan_call_back(final_payloads)
pii_scanner.produce_extract()This will produce the extract as if you called the scan() process itself.
Hardcoding the Payloads to the Extract Process
Sometimes, you will already know PII data exists and there is no requirement to run a PII scan. During these scenarios, you can manually inject your own payload when constructing the final_payloads for the known PII objects by using the below code.
[['COLUMN','kada_snowflakecomputing_com.dwh.extract.tableA.col1','3dbf7c4f-1d05-3b75-9920-9122e6eaed56','my detected pii']]When hardcoding a payload, check to ensure you have replicated the payload correctly:
Ensure that
my detected piimatches one of the PIIType namesEnsure the object type is correct
Ensure that object id is correct, for TABLE objects K follows a string period delimited format
<host name>.<database name>.<schema name>.<table name>
You should reference the object list or other produced outputs for examples of the format. Note that if any of the parts contain a period in the name, the period is transformed into an _ e.g. if my table name was KADA.AI we change it to KADA_AI to not cause issues with the period delimited format. Ask the KADA team if you still unsure of what to do.
References
Supported Data Sources
List of supported data sources
Snowflake
Oracle
Redshift
Object List File
The object list file can be generated via Ask K - Scanner → Generate Scanner Configuration
When using the default wrapper script you’ll need to pass in an object list file, the file spec is as follows
A Flat file that is comma separated, can be any extension provided it’s text readable e.g. .txt, .csv
UTF-8 encoded
Contains the following header
CODEOBJECT_TYPE,OBJECT_ID
HEADER | TYPE | OPTIONAL | DESCRIPTION | EXAMPLE |
|---|---|---|---|---|
OBJECT_TYPE | STRING | N | The object type being scanned, currently only support TABLE | TABLE |
OBJECT_ID | STRING | N | The ID of the object being scanned, for TABLES this is a 4 part ID in the form <host>.<database>.<schema>.<table> Where the value of host should match the value of the host onboarded in K. Each part of the ID should have any periods (.) replaced by an underscore (_) to not interfere with the ID format. | kada_snowflakecomputing_com.landing.fcs.lookup_codes |