Collector Method
List of Current Available Collectors
K Platform currently offers the following Collector Methods:
- Athena (via Collector method)
- AWS RDS Postgres (via Collector method)
- Azure Data Factory (via Collector method)
- Azure SQL (via Collector method)
- Azure Synapse (via Collector method)
- BigQuery (via Collector method)
- Bytehouse (via Collector method)
- Clickhouse (via Collector method)
- Cognos (via Collector method)
- Databricks (via Collector method)
- DB2 (via Collector method)
- DBT Cloud (via Collector method)
- Glue (via Collector method)
- Greenplum (via Collector method)
- Hevo (via Collector method)
- Hightouch (via Collector method)
- IICS (via Collector method)
- Informatica (via Collector method)
- Microsoft Dynamics (via Collector method) - v3.0.0
- Microsoft Dynamics 365 CRM (via Collector method)
- MySQL (via Collector method)
- Oracle Analytics Cloud (via Collector method)
- Oracle Database (via Collector method)
- Postgres (via Collector method)
- Power BI (via Collector method)
- Redshift (via Collector method)
- SAS (via Collector method)
- Sensitive Data (e.g. PII) Scanner
- Snowflake (via Collector method)
- Snowflake DMF (via Collector method)
- SQL Server (via Collector method)
- SSAS (via Collector method)
- SSIS (via Collector method)
- SSRS (via Collector method)
- Tableau Cloud (via Collector method)
- Tableau Server (via Collector method)
- Teradata (via Collector method)
- ThoughtSpot (via Collector method)
About Collectors
Collectors are extractors that are developed and managed by you (A customer of K).
KADA provides python libraries that customers can use to quickly deploy a Collector.
Why you should use a Collector
There are several reasons why you may use a collector vs the direct connect extractor:
You are using the KADA SaaS offering and it cannot connect to your sources due to firewall restrictions
You want to push metadata to KADA rather than allow it pull data for Security reasons
You want to inspect the metadata before pushing it to K
Using a collector requires you to manage
Deploying and orchestrating the extract code
Managing a high water mark so the extract only pull the latest metadata
Storing and pushing the extracts to your K instance.
Downloading the latest Collector and Core Library
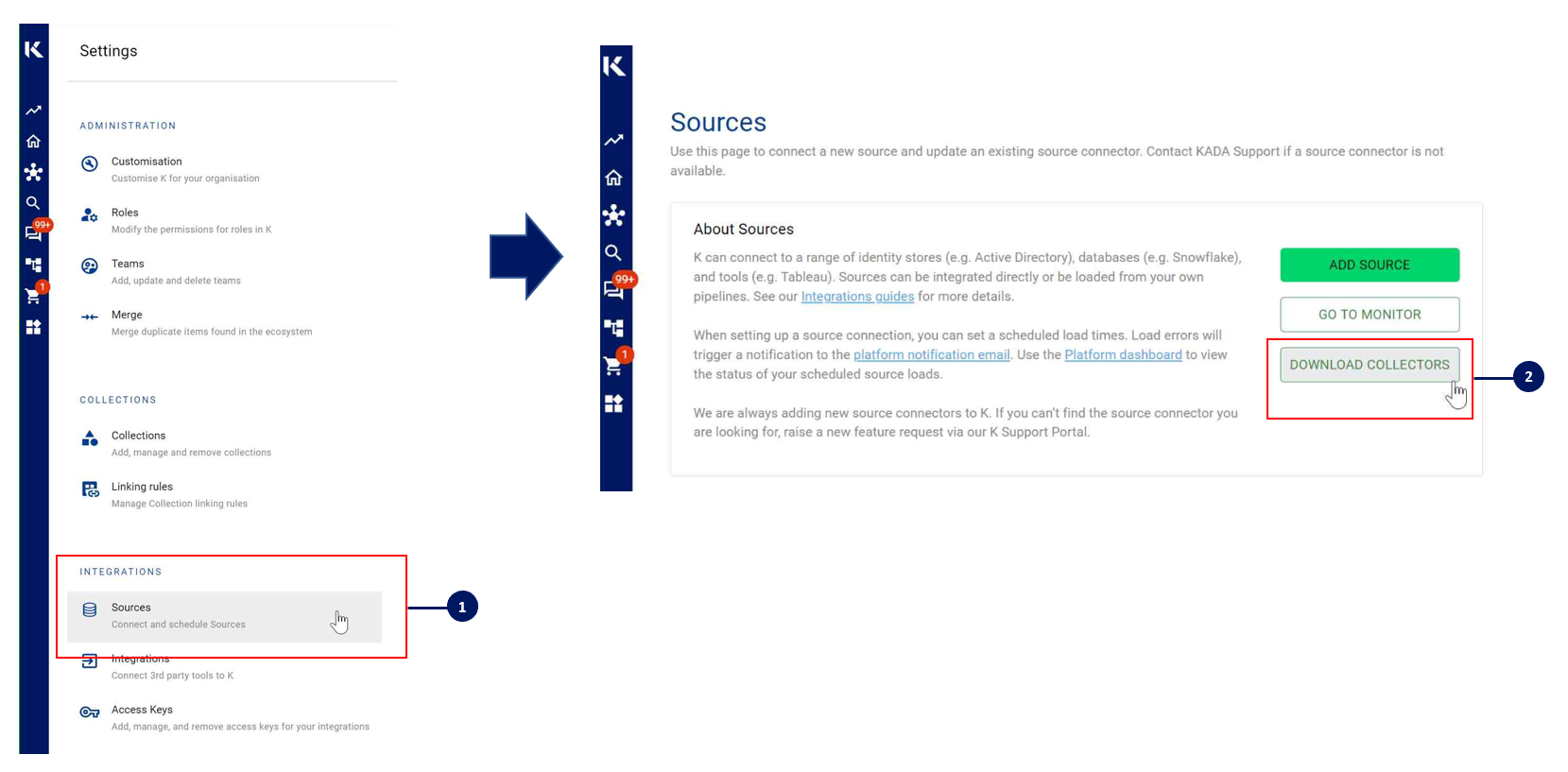
The latest core library needs to be installed prior to deploying a Collector. You can download the latest Core Library and Collector whl via Platform Settings → Sources → Download Collectors
Collector Server Minimum Specifications
For the collector to operate effectively, it will need to be deployed on a server with the below minimum specifications:
CPU: 2 vCPU
Memory: 8GB
Storage: 30GB (depends on historical data extracted)
OS: unix distro e.g. RHEL preferred but can also work with Windows Server.
Python 3.10.x or later
Access to K landing directory
About Landing Directories
When using a Collector you will push metadata to a K landing directory.
To find your landing directory you will need to
Go to Platform Settings - Settings. Note down the value of this setting
If using Azure: storage_azure_storage_account
if using AWS:
storage_root_folder - the AWS s3 bucket
storage_aws_region - the region where the AWS s3 bucket is hosted
Go to Sources - Edit the Source you have configured. Note down the landing directory in the About this Source section
To connect to the landing directory you will need
If using Azure: a SAS token to push data to the landing directory. Request this from KADA Support (support@kada.ai)
if using AWS:
an Access key and Secret. Request this from KADA Support (support@kada.ai)
OR provide your IAM role to KADA Support to provision access.
Airflow Example
The following example is how you can orchestrate the Tableau collector using Airflow and push the files to K hosted on Azure. The code is not expected to be used as-is but as a template for your own DAG.
# built-in
import os
# Installed
from airflow.operators.python_operator import PythonOperator
from airflow.models.dag import DAG
from airflow.operators.dummy import DummyOperator
from airflow.utils.dates import days_ago
from airflow.utils.task_group import TaskGroup
from plugins.utils.azure_blob_storage import AzureBlobStorage
from kada_collectors.extractors.utils import load_config, get_hwm, publish_hwm, get_generic_logger
from kada_collectors.extractors.tableau import Extractor
# To be configed by the customer.
# Note variables may change if using a different object store.
KADA_SAS_TOKEN = os.getenv("KADA_SAS_TOKEN")
KADA_CONTAINER = ""
KADA_STORAGE_ACCOUNT = ""
KADA_LANDING_PATH = "lz/tableau/landing"
KADA_EXTRACTOR_CONFIG = {
"server_address": "http://tabserver",
"username": "user",
"password": "password",
"sites": [],
"db_host": "tabserver",
"db_username": "repo_user",
"db_password": "repo_password",
"db_port": 8060,
"db_name": "workgroup",
"meta_only": False,
"retries": 5,
"dry_run": False,
"output_path": "/set/to/output/path",
"mask": True,
"mapping": {}
}
# To be implemented by the customer.
# Upload to your landing zone storage.
# Change '.csv' to '.csv.gz' if you set compress = true in the config
def upload():
output = KADA_EXTRACTOR_CONFIG['output_path']
for filename in os.listdir(output):
if filename.endswith('.csv'):
file_to_upload_path = os.path.join(output, filename)
AzureBlobStorage.upload_file_sas_token(
client=KADA_SAS_TOKEN,
storage_account=KADA_STORAGE_ACCOUNT,
container=KADA_CONTAINER,
blob=f'{KADA_LANDING_PATH}/{filename}',
local_path=file_to_upload_path
)
with DAG(dag_id="taskgroup_example", start_date=days_ago(1)) as dag:
# To be implemented by the customer.
# Retrieve the timestamp from the prior run
start_hwm = 'YYYY-MM-DD HH:mm:SS'
end_hwm = 'YYYY-MM-DD HH:mm:SS' # timestamp now
ext = Extractor(**KADA_EXTRACTOR_CONFIG)
start = DummyOperator(task_id="start")
with TaskGroup("taskgroup_1", tooltip="extract tableau and upload") as extract_upload:
task_1 = PythonOperator(
task_id="extract_tableau",
python_callable=ext.run,
op_kwargs={"start_hwm": start_hwm, "end_hwm": end_hwm},
provide_context=True,
)
task_2 = PythonOperator(
task_id="upload_extracts",
python_callable=upload,
op_kwargs={},
provide_context=True,
)
# To be implemented by the customer.
# Timestamp needs to be saved for next run
task_3 = DummyOperator(task_id='save_hwm')
end = DummyOperator(task_id='end')
start >> extract_upload >> end