About K
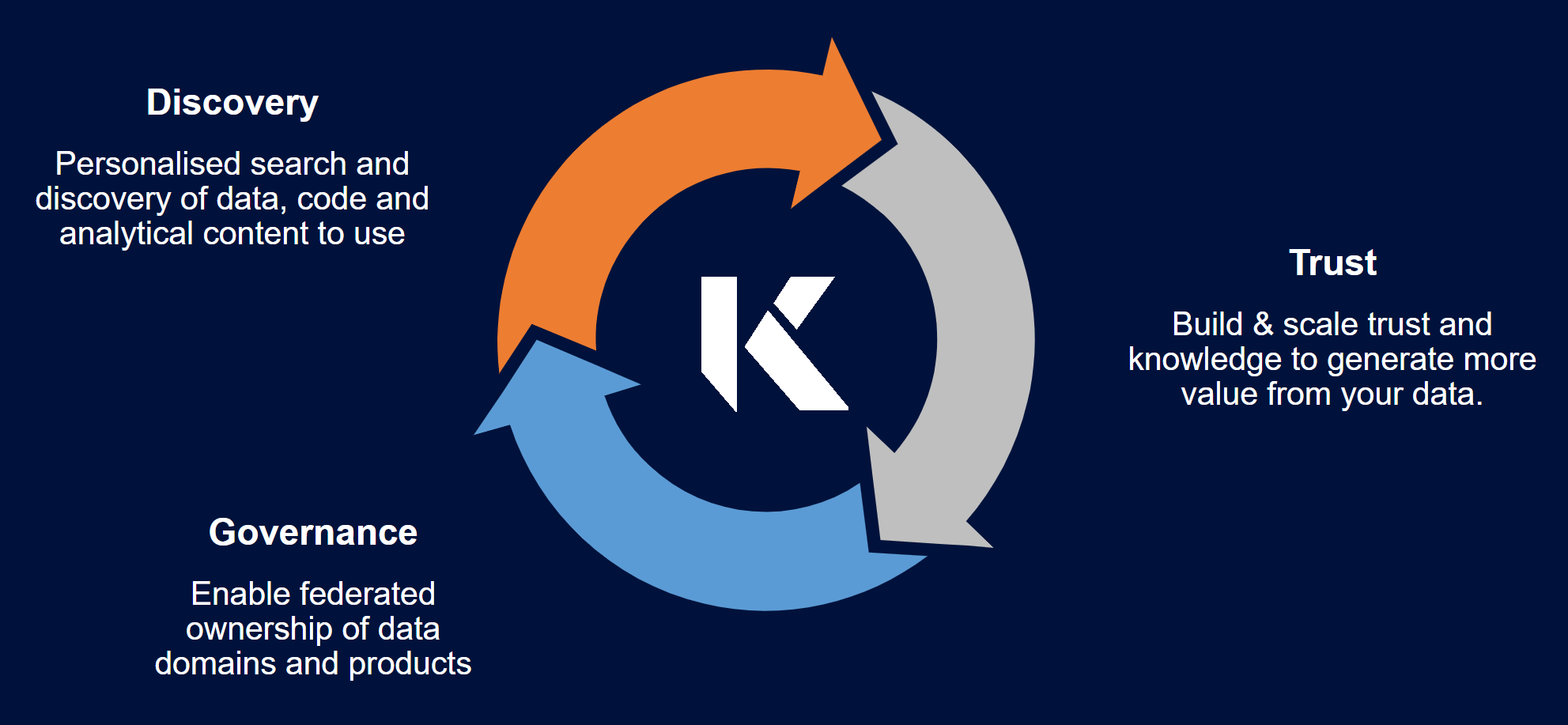
K is a Data Knowledge platform enabling data discovery, knowledge management and data governance for all data users.
This page will provide a brief introduction to K and highlight some of it’s key features that make it unique.
Introduction to K
K is a Data Knowledge platform for discovering, profiling and understanding how data products (data sets, analysis, reports etc) across an Enterprise is used.
K focuses on identifying and storing how users work with data; leveraging this information to enable data producers to improve their products; data owners to take accountability for the proper use of their data; and to scale hidden knowledge to all data workers. The product vision is to become the central platform for all Enterprise data users to easily discover, understand and govern the use of data.
Data Discovery
K is your metadata copilot for finding the right data to use for any use case.
K's unified Search Experience enables business and technical users in your organisation to find the right data asset across databases, reporting platforms, ML feature stores, ETL tools and more.
To help optimise search results, K calculates Trust Score to improve search relevancy and ensure that the most suitable, up to date, and relevant data asset is promoted.
Users can create Filters using all of the metadata collected to customise their search experience. Saved filters that helps a user save time can be easily shared to colleagues.
K's best in class automated Lineage Maps make it easy to navigate the data ecosystem and understand upstream dependencies, or downstream impacts from any data asset. Users can also personalise their map with custom filters, highlight trusted paths and drill through to knowledge.
Knowledge Management
K uses automated intelligence and smart engagement to build meaningful data profiles by analysing how your data is created and used.
From one Data Profile Pageyou can directly access all information specific to that data asset including, data issues, data quality, data lineage and more.
K automatically suggests glossary terms that can be linked to a Data Asset and can Auto Generate Descriptions through K.ai.
Crowdsourcing and collaboration is made easy through smart features that link your current workflow tools or Collaboration Channels (e.g. MS Teams, Slack or Discord). This blend of automation and crowdsourcing takes the boring manual work out of building your data catalog.
K knows who the top users of each data asset are. Through K, you can directly Ask Questions to Top Users that are most likely to know the answer. Similarly, when a decision, note, or change is added, K automatically notifies any recent users of the report, so they are kept in the loop.
Through key Usage Metrics so you can also understand how a data asset is used, and where it is in its lifecycle.
Data Governance
K can help data governance teams fast-track the process to understand their data ecosystem and design the appropriate governance framework. Key features in K that help data governance teams include:
Detect PII - K has inbuilt Personally Identifiable Information scanners that can help quickly identify potential PII located in your data tables and columns.
Automate Data Tagging - Remove the manual nature of tagging data and automate the process through business rules to minimise data governance gaps
Dashboards and Insights - Tailored dashboards can help target and simplify governance effort. Data Owners and Stewards can view key governance and data quality metrics for the data assets they own
Data Change Timeline - When it's needed, data governance managers can drill into historical data change timeline to investigate what has happened or when data decisions were made.
Centralise DQ Results - Use K to capture DQ results from tools like Great Expectations and DBT. Alert the right people to DQ failures and leverage workflow tools like JIRA to address data problems.
Notify impacted stakeholders - Automate data governance change management by using K to identify impacted stakeholders on any relevant changes implemented by the data governance team (e.g. Updates to PI data policy)
Bulk Functions - Speed up the process to update data properties, link to collections, add tags and create lists through a range of K Bulk Functions